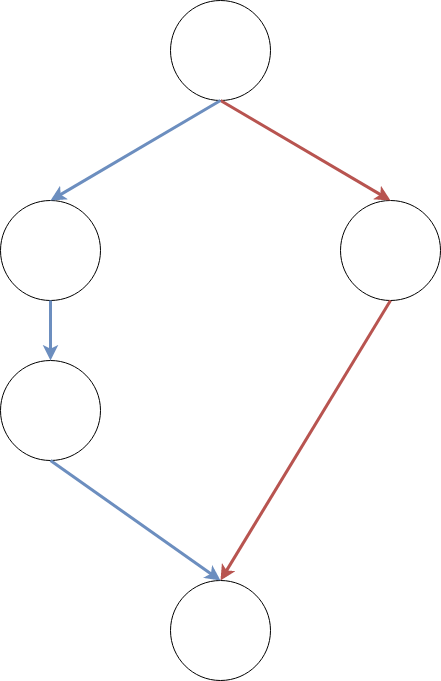
This strategy applies specifically to any query in which you have to retrieve some data from a table via two different routes. What do I mean by routes? Let's think of our database as a large graph, where the nodes are the tables and the edges are the foreign key relationships between them. Having a "route" to certain data is just a path between two nodes, so having two different routes to get at the data you want might look something like this:
Normally this would be done using
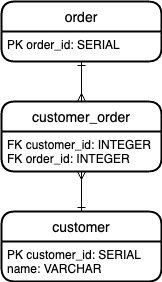
JOIN clauses. To imagine that let's create an example schema. Perhaps you work at a company which uses
a SQL database to manage its orders. Whenever a customer places an order it gets recorded within a table called
orders
. In addition to tracking orders, perhaps your company wants to track which customers placed which orders by name.
So we have another
table called customer. Let's say that a group of customers can all place a single order together, and
that one customer
can place many orders. As such, there must be a many-to-many relationship with a table between them, which we'll
call
customer_order.
CREATE TABLE orders(
order_id SERIAL PRIMARY KEY,
);
CREATE TABLE customer (
customer_id SERIAL PRIMARY KEY,
name VARCHAR
);
CREATE TABLE customer_order (
customer_id INTEGER NOT NULL,
order_id INTEGER NOT NULL,
CONSTRAINT fk_customer FOREIGN KEY(customer_id) REFERENCES customer(customer_id),
CONSTRAINT fk_order FOREIGN KEY(order_id) REFERENCES orders(order_id)
);
Now let's say that you're designing a feature for your system for which you need to search for all the orders that a customer has placed, and that you need to be able to search by the customer's name. It's pretty easy to implement this.
SELECT orders.order_id
FROM orders
JOIN customer_order ON orders.order_id = customer_order.order_id
JOIN customer ON customer_order.customer_id = customer.customer_id
WHERE customer.name = ?;
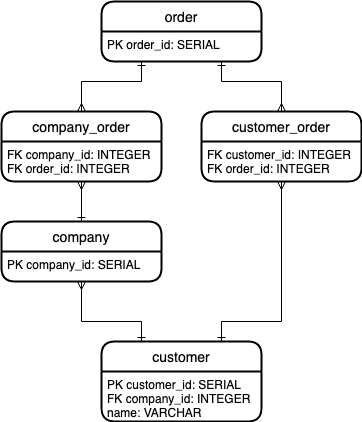
Now let's imagine that you want to start grouping customers. It might be interesting to track
which company a customer belongs to, if they belong to any at all. So you add another table called
company with
a one-to-many relationship with customers, assuming each customer can only belong to one company. However, when
someone places an order they can choose to either do it as an individual customer, or do it on behalf of
a company. If they choose the latter, then they don't have to supply any of their own individual customer
information. All of that information is already stored when the company "registered" in our system and assigned a
few "point of contact" customers to themselves ahead of time. This means that in order to continue accurately
tracking which customers are associated with orders, we need to link the company and order
tables. Like the relationship between customers and orders, this will also have a many-to-many relationship with an
intermediary table called company_order. Let's see what our new schema looks like.
CREATE TABLE orders(
order_id SERIAL PRIMARY KEY,
);
CREATE TABLE company (
company_id SERIAL PRIMARY KEY,
)
CREATE TABLE customer (
customer_id SERIAL PRIMARY KEY
name VARCHAR,
company_id INTEGER,
CONSTRAINT fk_company FOREIGN KEY(company_id) REFERENCES company(company_id)
);
CREATE TABLE company_order (
company_id INTEGER NOT NULL,
order_id INTEGER NOT NULL,
CONSTRAINT fk_company FOREIGN KEY(company_id) REFERENCES company(company_id),
CONSTRAINT fk_order FOREIGN KEY(order_id) REFERENCES orders(order_id)
);
CREATE TABLE customer_order (
customer_id INTEGER NOT NULL,
order_id INTEGER NOT NULL,
CONSTRAINT fk_customer FOREIGN KEY(customer_id) REFERENCES customer(customer_id),
CONSTRAINT fk_order FOREIGN KEY(order_id) REFERENCES orders(order_id)
);
Going back to our feature, the query to retrieve all orders a customer has placed gets a little more complicated now. We need to account for the 2nd path where they may have placed it on behalf of a company.
SELECT orders.order_id
FROM orders
JOIN customer_order ON orders.order_id = customer_order.order_id
JOIN customer AS c1 ON customer_order.customer_id = customer.customer_id
JOIN company_order ON orders.order_id = company_order.order_id
JOIN company ON company_order.company_id = company.company_id
JOIN customer AS c2 ON company.company_id = customer.company_id
WHERE c1.name = ? OR c2.name = ?;
That's a lot of JOINs, each of which has bad performance implications as we traverse the
table. Not to mention, we actually have to traverse through the customer table twice! Notice that
there's an alias each time, either c1 or c2. That's because if we didn't alias them, then in the WHERE
clause the database would have no idea which instance of customer we're talking about. Are we
talking about the customer table we JOINed on when customers ordered directly, or the
customer table we JOINed on when customers ordered through companies? It'd throw an
"ambiguous column name" error. c1 and c2 allow us to specify the two routes to the customer table with
different aliases. This means they both have to be in the WHERE clause if we want to make sure we're
getting all orders associated with a given customer. It's possible that customer could make orders both
individually and on behalf of a company.
Alright so it's not the most efficient solution, but is it really that bad? Yes. Primarily because it
doesn't scale. Let's say we added a third route through which customers could place orders, say on behalf of some
entity that we want to track separately from companies, like a government of a foreign country. We'd then have a
government table and a government_orders table and in our query we'd then traverse through
the customer table 3 times. Our WHERE clause would say WHERE c1.name = ? OR c2.name
= ? OR c3.name = ?". Now imagine we add 5 more routes to get to the customer table from the
orders table. Our query would be a massive mess of JOINs, we'd have to traverse the
customer table N times, and our WHERE clause would be utterly unreadable. Wouldn't it be
great if we could just traverse customer once and search by the customer's name once?
Let's flip this problem on its head by starting at the end. Instead of getting all the orders
for a given customer, let's first get the given customer and then get all the orders for that customer. Step one,
getting the customer, is easy.
SELECT customer_id, company_id FROM customer WHERE customer.name = ?;
Now that we have the customer let's get all orders associated with that customer using the output of that first query.
SELECT orders.order_id
FROM orders
JOIN customer_order ON orders.order_id = customer_order.order_id
WHERE customer_order.customer_id = ?; -- the ? will be populated by the id returned from the previous query.
We can optimize this little query and remove the JOIN because both the orders
table and the customer_order table have the field order_id. So instead of searching for
the orders from the orders table, we can just use customer_order.
SELECT customer_order.order_id
FROM customer_order
WHERE customer_order.customer_id = ?; -- the ? will be populated by the id returned from the previous query.
We've optimized the query to not have to JOIN with the customer or
orders tables at all. However, we've split it out into two different queries, which means we'd have to
write some logic in code to stitch them together. Logic that could break or cause bugs. Wouldn't it be nice if we
could do both queries together? Enter the WITH clause!
WITH customer_query AS (SELECT customer_id, company_id FROM customer WHERE customer.name = ?)
SELECT customer_order.order_id
FROM customer_order
JOIN customer_query ON customer_query.customer_id = customer_order.customer_id
WHERE customer_order.customer_id = customer_query.customer_id;
At first glance it may seem like we're still JOINing on the customer table.
After all, we're doing a JOIN on the customer_id. But if you look closely you'll see that
the JOIN actually happens on the output of the WITH clause, labeled as
customer_query. This means that it's only JOINing on the specific subset of data that we
got when we did the first query inside the WITH. Instead of having to traverse the entire
customer table, it only needs to look at one row! Yes it's a JOIN, but a JOIN
on a set of data with only one row barely has an effect on performance at all.
What about the other path through the data? With what we have now we can get all orders placed directly
by a customer very fast, but we still need to also get all the orders placed on behalf of a company. How can we
possibly do that in the same query? Enter the UNION clause!
WITH customer_query AS (SELECT customer_id, company_id FROM customer WHERE customer.name = ?)
SELECT customer_order.order_id
FROM customer_order
JOIN customer_query ON customer_query.customer_id = customer_order.customer_id
WHERE customer_order.customer_id = customer_query.customer_id
UNION
SELECT company_order.order_id
FROM company_order
JOIN customer_query ON customer_query.company_id = company_order.company_id
WHERE company_order.company_id = customer_query.company_id;
Note that we now JOIN on the same single-line subset of the customer table
defined in our WITH clause as customer_query, but this time
we're joining by the company_id. Also note that we did the same performance optimization to get the
order_id from company_order rather
than having to JOIN on the orders table. Now we have all the data we need, we
didn't have to JOIN on orders or on the full customer
table at all, and our query will scale as we add more and more paths through our database.